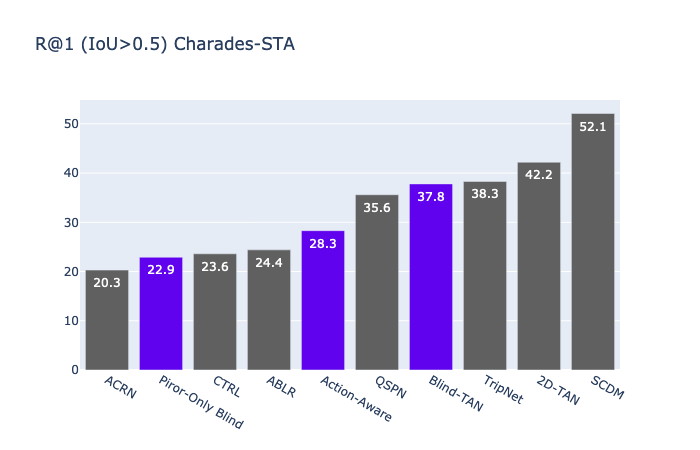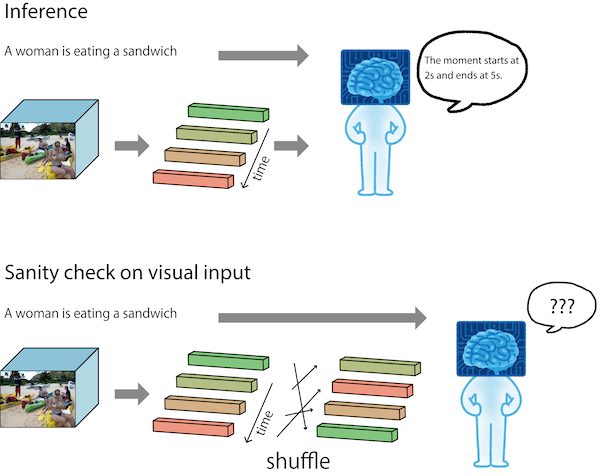
SOTA Models Often Ignores Visual Input
Our analyses revealed that some deep models highly rely on language priors on video moment retrieval. We describe visual sanity check for investigating if a model uses visual input. Visual sanity check is easy to try. We randomly reorder visual features of a video and see how output changes.