Published: Sep 1, 2020 by
SOTA Models Often Ignores Visual Input
Our analyses revealed that some deep models highly rely on language priors on video moment retrieval. We describe visual sanity check for investigating if a model uses visual input. Visual sanity check is easy to try. We randomly reorder visual features of a video and see how output changes.
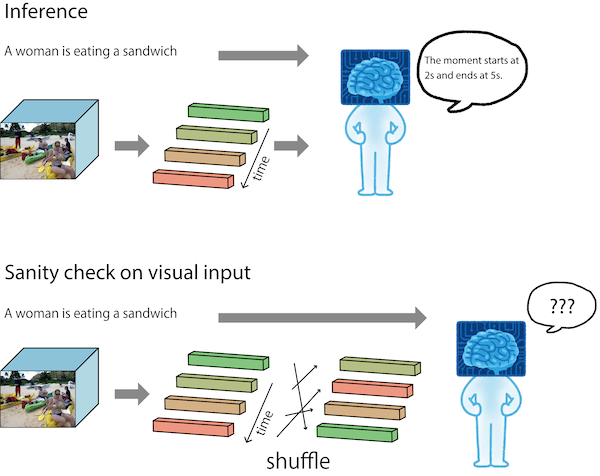
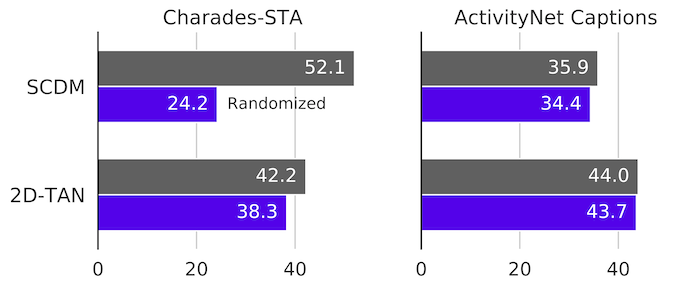
If a model’s prediction is based on input videos, the performance should drop significantly. On the other hand, if a model’s prediction is mostly based on language priors, the perturbation should hardly affect outputs. Here shows a result from our paper. Except SCDM on Charades-STA, the models highly rely on langauge priors.