Overview
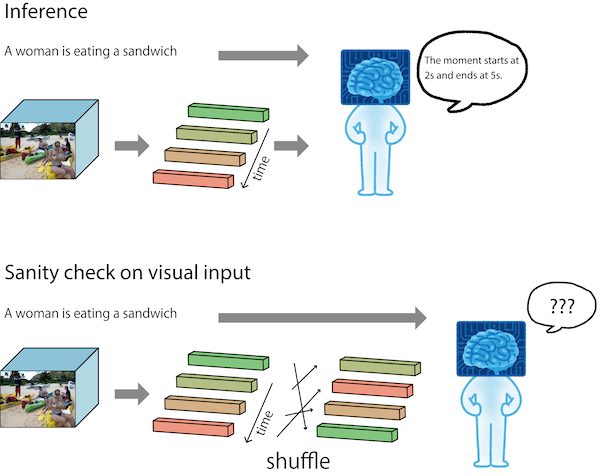
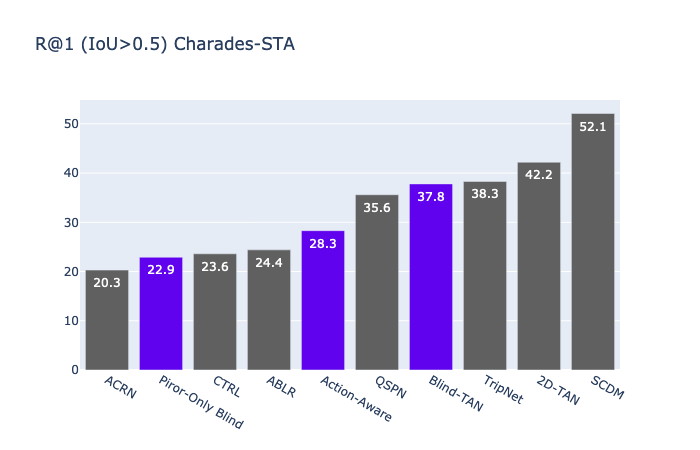
The query-based moment retrieval is a problem of localising a specific clip from an untrimmed video according a query sentence. This is a challenging task that requires interpretation of both the natural language query and the video content. Like in many other areas in computer vision and machine learning, the progress in query-based moment retrieval is heavily driven by the benchmark datasets and, therefore, their quality has significant impact on the field. In this paper, we present a series of experiments assessing how well the benchmark results reflect the true progress in solving the moment retrieval task. Our results indicate substantial biases in the popular datasets and unexpected behaviour of the state-of-the-art models. Moreover, we present new sanity check experiments and approaches for visualising the results. Finally, we suggest possible directions to improve the temporal sentence grounding in the future.
Video Overview
Citation
@inproceedings{otani2020challengesmr,
author={Mayu Otani, Yuta Nakahima, Esa Rahtu, and Janne Heikkil{\"{a}}},
title = {Uncovering Hidden Challenges in Query-Based Video Moment Retrieval},
booktitle={The British Machine Vision Conference (BMVC)},
year = {2020},
}